a) 文章資料および文字化された談話資料について。
編集ソフトとしてワープロよりもテキストエディタ(正規表現と grep の使用環境のため,秀丸エディタ [シェアウェア,Windows10まで対応] またはサクラエディタ[フリーウェア,Windows10まで対応,なお左のリンクから入るサイトではセキュリティソフトとの関係でうまくダウンロードできないことがあるらしい。そのときはサクラエディタの左下にある英語のサイトからのダウンロードを試みる。それでもうまくいかないばあいは,ここにリンクしてあるサイトからダウンロードを試みる。],Mery[フリーウェア,Windows10まで対応,「MeryWiki」,または「Vector」「窓の杜」のページからダウンロード],K2Editor [フリーウェア,Vista以降への対応は保証されていないが作動するようである]を推奨)が機動力に富む。コンコーダンサと連繋させるときは,エディタの使用が必須。他に,xyzzy 等がフリーウェアとして開発されているが,先に挙げた4種類のエディタ以外は筆者が使用したことがないので使い勝手など不明。
正規表現の使い方については,書籍では,佐良木昌・新田義彦(2003)『正規表現とテキスト・マイニング』(明石書房),荻野綱男・田野村忠温(2011)『講座ITと日本語研究 3 アプリケーションソフトの応用』明治書院,サイトでは, 睡人亭 (山田崇仁氏),Zaco's Page (Zaco氏)を参照。ただし,正規表現にはエディタ間で方言と呼ばれる異なりがあるので注意。このサイトの「セミナーとメモ」のページにも簡単な事例を示してある。
日本語に対応したKWIC関係のコンコーダンサとして以下のものが代表的である。いずれも正規表現の初歩的な知識があると有効に活用できる。
コンコーダンサは,初期設定のままではうまく作動しなかったり,前処理を怠ると誤った結果が導かれたりする。それぞれ,添付されているマニュアルやチュートリアルを参照し,特性を理解して使用すること。
・KWIC Finder:EBシリーズ。Windowsに対応。軽快に動き,検索一致ビューに対応する本文が同一ウィンドの下部に表示される。フォルダ全体を対象とすることができるので,品詞性や形態素の別を配慮せず大量のデータを検索するときに便利。Windows10では,うまく作動しないという報告があり,そのばあいは一般的なテキストエディタで grep を活用して代行させるしかないだろう。Kwic Finder のイメージはここをクリック。
【Kwic Finderは,2018年11月に "Kwic Finder 4" のリリースが行われ,無条件でシェアウェアとなり,フリーライセンスの属性がなくなった。】
・KH Coder(Chasenを含む,有償でOSX対応):立命館大学 樋口耕一氏。KWICコンコーダンサを含む計量テキスト分析・テキストマイニングのためのソフトウェア。Windows以外にも対応,詳細はマニュアル参照。正確な分析を行うために,プロジェクト毎に必ず前処理を実行する。これによってテクスト内の語をどのように認識させるかが決まる。半自動で計量テキスト分析が可能。また,計量的な処理を行うためには,多変量解析の知識が必要である。専門的な訓練が前提とされるので,自動的に解析された結果を読み取る技術等を習得した上で,適切に使用すること。
・AntConc:早稲田大学 Anthony, L. 氏。KWIC,テキストにおける単語の分布など。Windows以外にも対応,詳細はマニュアル参照。ソフトのダウンロードとインストールは容易。日本語および中国語を扱うためには,SegmentAnt によってテキストを分かち書きにしておく必要がある。ただし,分かち書きが文脈によって不整になる可能性があるため,注意が必要である。SegmentAntは,事前にテキストのコードを,UTF-8 に変換してから適用する(秀丸などはデフォルトがShift_JIS,miはデフォルトがUTF-8)。AntConc,SegmentAnt ともにヘルプを参照されたい。日本語で書かれたガイド(分析対象は英語だが,日本語のテキストも分かち書きしてあるので,同様に考えて良い)も,同サイト内 AntConc のページからリンクされている。Concordance Plot Tool は,テクスト(間)における単語の分布を,横長のバーに縦線によりプロットするもので,テクスト構造の一端を直観的に掌握しやすい。
・日本語KWIC索引生成ソフトウェア KWIC:大阪大学田野村忠温氏のサイトに接続し,そのページからダウンロード・インストールする。説明にしたがえば問題なく進めることができる。検索対象は,青空文庫の一部をプレーンテキストとしたコーパスが,”corpora”にある。これを C:\corpora に置くものとして運用されている。”corpora”には,任意のテキストファイルのデータを自分で追加することができる。検索結果は,インストール先のフォルダに保存される。詳細はマニュアルを参照。このコンコーダンサは,Windows10でも正常に作動する。また正規表現(または疑似正規表現:マニュアルを参照)も使用できる。ソフトを追加して,検索した該当箇所を含む文脈を広く示すこともできるが,秀丸(シェアウェア)のインストールが必須とされている。
・『ひまわり』 :国立国語研究所(XML文書を対象とした検索システム)
形態素解析システム 茶筌,awkなどのスクリプト言語があると,作業の効率をあげることができる。KH Coderには茶筌が組み込まれている。
形態素解析を web 上で実行するためには,国立国語研究所で公開されている「形態素解析ツール Web茶まめ」を活用することが推奨される。MeCabによる形態素解析ができる。
国立国語研究所のサイト内では,データベースのページを参照する。また,特定領域研究「日本語コーパス」日本語学班のサイトにアクセスしガイドブック等を参照する。
以下のサイトは,リンク集(「電子コーパス」の項)からもアクセス可能。それぞれ注意事項や条件を参照して使用する。
・コーパス開発センター
・NINJAL-LWP for BCCWJ (内容語の共起関係や文法的振る舞いの表示,TWCもリンク)
・日本語話し言葉コーパス(CSJ)
Mac OSXについて付記しておく。筆者が使用する環境にないので,作動等は保障できない。情報のみ掲載しておく。
テキストエディタで日本語を扱うことができるものとして,mi が開発されている。正規表現にも対応しているとのこと。
KWICコンコーダンサとしては,Simple KWIC Lister (『日本研究センター教育研究年報』第1号(2012)からリンク)が開発されている。大学院生からの情報では,使い勝手は良いらしい。
b) 談話資料は,書き言葉と異なる方式で文字化されている場合がある。また,研究者が自分で文字化するとしても,談話資料特有のコード化の方法がある。既存のソフトウェアは,書き言葉の分析のみを前提にしているので,談話資料には,ただちに適用できないことが多い。文法・語彙分析用のソフトウェアを使用する際,談話資料独自の表記方法は,あらかじめ書き言葉の表記方法に標準化しておくか,何らかの方法で登録しておく必要がある。
文字化作業のツールとして,フリーのテープ起こしソフト「おこしやす,Okoshiyasu2」がある。再生等のキー割り当てや自動巻き戻し時間の設定ができる。フットスイッチは任意に使用できる。ほかに,「テープ起こしプレーヤー」(株式会社アスカ21)が無償で公開されている。
c) ビデオ(動画)資料は,例えば次のようなソフトウェアを使用すると,解析の準備段階に至ることができる。動画・音声データに多様な注釈を書き込む欄を設定し,そこに情報を記入して各種の分析を実行するためのツール。動画・音声データによるマルチモーダルな談話分析を行いたいときに有効。Windows,Macintosh ともに使用できるフリーウェア。
・ELAN(EUDICO Linguistic Annotator) (The Language Archiving Technology (LAT)) (* European Distributed Corpora Project)。
動画と音声波形が同期して表示され,動画の時間進行が音声波形表示部分にカーソルで表示されるので,言語情報と非言語情報とを関係づけて観察したいときに便利である。トランスクリプションその他を注釈層に記入することで,統合的にデータを表示することができる。
日本語版が用意されたフリーソフトであり,下記のサイトに日本語の解説がある。ELAN のサイトには Support のページがある。ELANはしばしばバージョンアップされ,機能が追加されるので,常に更新しておくことが望ましい。画面のイメージはキャプチャのとおりである。ビデオビューアーには,イラストを用いてある。
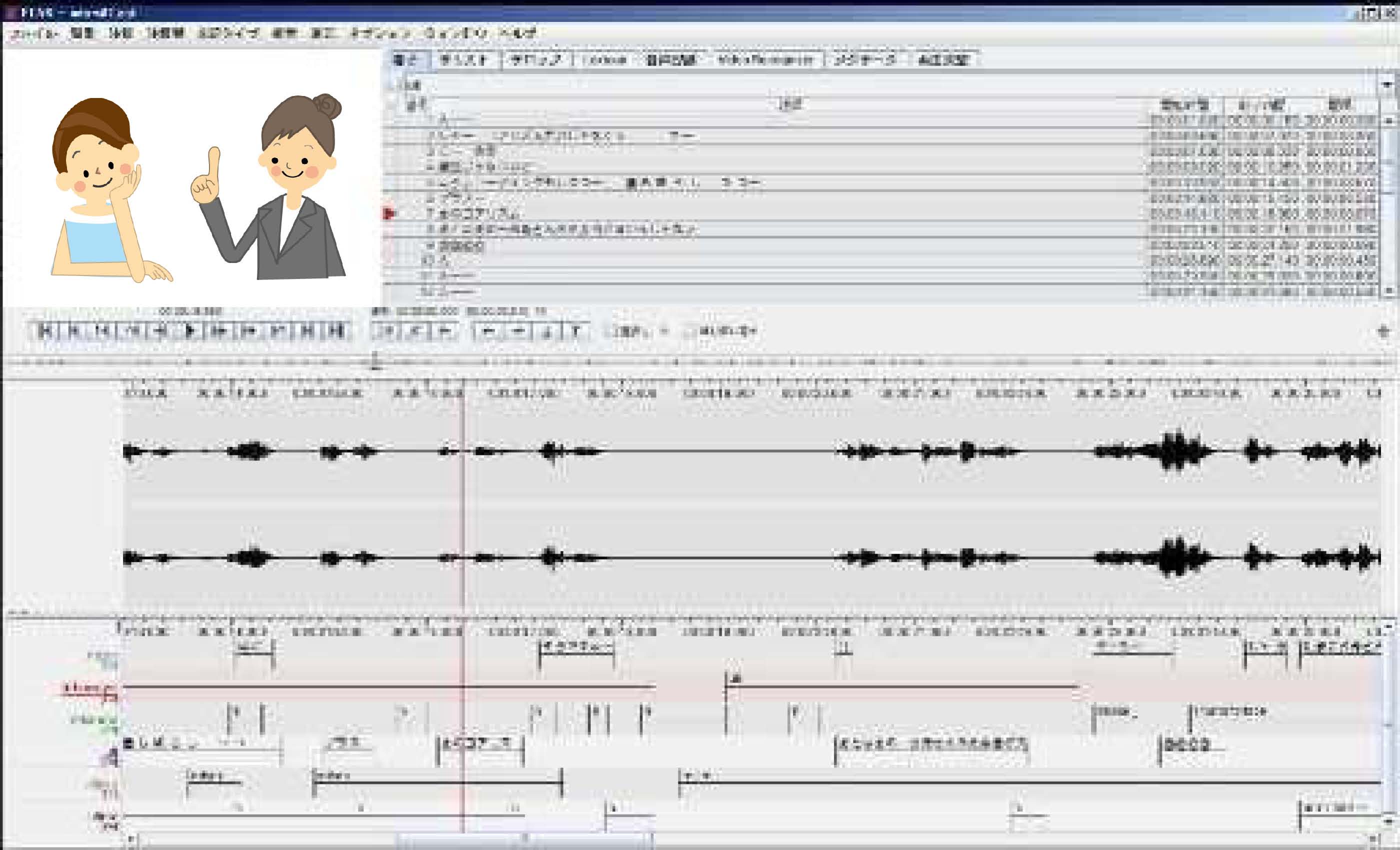
会話・ジェスチャー分析研究者のためのELAN即席入門 (滋賀県立大学 細馬宏通氏)
ELANによる動画解析の手順 (早稲田大学 菊池英明研究室 宮澤幸希氏)
注釈層の情報は,時間情報とともにテキストファイルに書き出すことができるので,そのままトランスクリプションのデータに転用可能である。ターンごとに改行した形式で書き出され,同時発話がなければ,ポーズの時間も自動的に算出される。
ビデオを収録するとき,録音レベルが低いと音声認識が弱くなり,波形が明確に表示されない可能性がある。ビデオカメラの内蔵マイクでは,弱いことがある。周辺の雑音等にも注意する必要がある。ただし,右クリックメニューのズームで表示を見やすくすることができる。
ステレオの音声波形は2つのチャンネルに分離して表示される。ステレオで収録できる場合は,(8) 機材の項目にあげたプラグアダプターとタイピン型マイクやヘッドセットマイクを併用して左右の音声を相対的に分離しておくと視覚的に鮮明になるだろう。
このシステムの運用のためには,動画ファイルと音声ファイルの準備が前提となる。そこで,最初に収録したビデオデータ(*.wmvなど)から動画ファイルと音声ファイルとを分離しておく必要がある。動画ファイルは *.mpg や *.mov 等,音声ファイルは *.wav の形式で準備する。環境に応じて,例えば次のようなソフトウェアを別途インストールしておくことが求められる。
1) ムービーメーカー (ムービー編集ソフト,通常は Windows マシンにインストール済み)
2) Audio Encode & Decode TooL(えこでこツール) (MPEG動画から音声ファイルを分離する。「出力」のメニューで「wav」形式を指定。)
3) Pazera Free Audio Extractor (各種動画ファイルから音声ファイルを抽出する)
4) TMPGEnc (MPEG動画から音声ファイルを分離する)
5) MPx2WAV32G (Vector 内。音声ファイルのMP2,MP3ファイルをWAVEファイルに変換する)
音声ファイル形式の変換は,任意のICレコーダーに付属のパソコン連繋のソフトウェア(たとえばソニーの Digital Voice Editor)に組み込まれた機能で実行できるばあいがある。
ELANも,音声学を含む言語学のみならず,社会学,相互行為分析,心理学,認知科学等の基礎的な訓練を受けた上で使用することが望ましい。
談話の内容的な記述と分析,音声的な解析や動画の処理を独立に行うのであれば,それぞれの目的に沿った専用のソフトウェアの方がシンプルで扱いが容易であり,機能的にもすぐれていることが多い。
・DVDに保存した動画をELANで分析する手順を示しておく。ELANで読み込む前に,動画ファイルのMPGと音声ファイルのWAVを準備する。
ファイルがDVDに保存されているものとする。まず,DVDのファイルをコンピュータにコピーする必要がある。そのアプリケーションとして,ImgBurn (DVD Decrypter の後継アプリケーション)などを使用する。アプリケーションが不要のばあいもある。この操作により,VOBファイルなどができる。その拡張子を書き換えるだけで,MPGファイルが得られる。
MPGファイルから,Pazera Free Audio Extractorなどを使用して,音声ファイルとしてWAVファイルを抽出する。
ELANで,このMPGファイルとWAVファイルを読み込み,分析作業をすすめることができる。
d) ミーティングレコーダー(MR360)は,事務機器として販売されている。たとえば,4人の座談であればテーブルの中央にレコーダーを置き,参加者をそれぞれカメラの正面数10センチ程度の距離に位置させて収録する。そのファイルをパソコンに取り込み,メディアプレーヤーなどで再生すると,画面が4分割され,各象限に1人ずつの上半身を映し出すことが可能である。精度の高い分析や高度な処理には不向きだが,ひととおり音声言語,身振り,視線などを観察・記述することができる。外光を遮り,明るい室内照明のみで収録することが望ましい。必要に応じてICレコーダーなどを併用する。
下の図は,ミーティングレコーダー(MR)収録時における参加者の位置関係(左図)とディスプレイ上での4分割モードによる表示(右図)の対応例。
